
A landmark study from Harvard Medical School has found that OpenAI's AI models offered more accurate diagnoses than emergency room physicians — particularly during initial triage when information is scarce and urgency is highest. The research, published in Science, is the most rigorous evidence yet that AI can match or exceed human clinical judgment in real medical settings.
What the Study Found
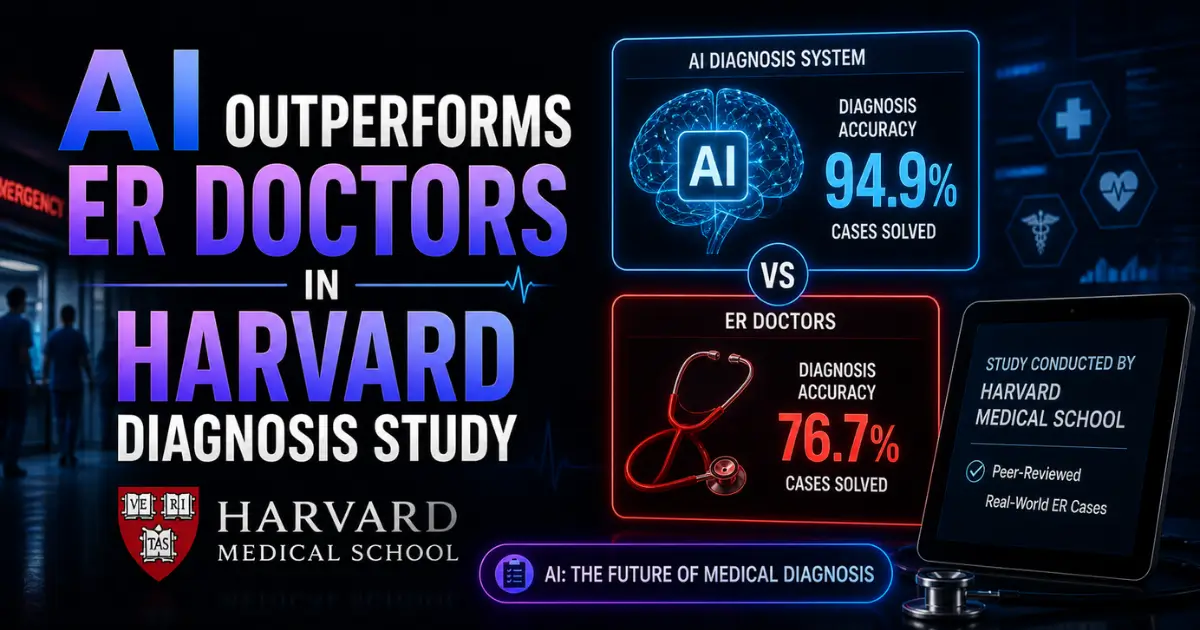
Researchers at Harvard Medical School and Beth Israel Deaconess Medical Center tested OpenAI's o1 and GPT-4o models against two attending physicians using 76 real emergency room cases. The AI received the same information available in electronic medical records at each diagnostic stage. No data was pre-processed or curated for the models.
Two independent physicians evaluated all diagnoses human and AI without knowing which came from doctors and which came from machines. The results were striking. OpenAI's o1 model produced the correct or very close diagnosis in 67 percent of initial triage cases. One physician hit the mark 55 percent of the time. The other managed 50 percent.
The gap was most pronounced at the first diagnostic touchpoint the moment when a patient arrives in the ER with the least information available and the most urgency to make the right call. At later stages, when more test results and clinical data were available, the performance gap narrowed.
Lead author Arjun Manrai, who heads an AI lab at Harvard Medical School, said the model was tested against virtually every benchmark and eclipsed both prior models and physician baselines.
Why Triage Matters Most
The finding that AI outperforms at triage is particularly significant. Initial ER triage determines which patients are seen first, which tests are ordered, and which treatment pathways are initiated. A wrong triage decision can mean delayed care for a critical patient or unnecessary escalation for a minor complaint.
Emergency departments are chronically understaffed. Wait times are measured in hours. And triage decisions are made under extreme time pressure by physicians juggling dozens of patients simultaneously. An AI tool that improves triage accuracy — even by a modest margin — could save lives at scale.
The results contrast sharply with the BMJ Open study published earlier this year, which found that consumer AI chatbots give problematic health advice roughly half the time. The critical difference is context. Consumer chatbots answer general health questions from untrained users. The Harvard study tested a clinical-grade model working from structured medical records in a controlled diagnostic setting.
Not Ready for Real Decisions
The researchers were careful to avoid overclaiming. The study does not say AI is ready to make life-or-death decisions in the ER. Instead, it argues that the results create an urgent need for prospective clinical trials — real-world testing where AI assists actual patient care rather than reviewing cases after the fact.
The study also noted important limitations. The models were tested on text-based information only. Existing research suggests current AI models are more limited in reasoning over non-text inputs like medical imaging, physical examination findings, and patient behavior that physicians observe in person.
Beth Israel physician Adam Rodman, a co-lead author, told The Guardian that there is currently no formal framework for accountability around AI diagnoses. Patients still want humans to guide them through life-or-death decisions. The AI may be more accurate on paper, but trust, empathy, and legal responsibility remain human domains.
The Healthcare AI Race
The study arrives as AI companies are racing into healthcare. OpenAI launched dedicated health tools for consumers and clinicians earlier this year. Anthropic has expanded Claude into healthcare applications. Google is embedding Gemini across its product suite, including health-related search and personal intelligence features.
Startups are also pursuing medical AI. 10x Science raised $4.8 million to accelerate drug discovery using AI-powered molecular analysis. The intersection of AI and healthcare is attracting billions in investment and generating some of the highest-stakes questions about reliability, accountability, and trust.
What It Means
The Harvard study shifts the AI-in-medicine debate from whether AI can help to how soon it should be tested in practice. A 67 percent accuracy rate at initial triage compared to 50-55 percent for experienced physicians — is a gap large enough to matter clinically. If replicated in prospective trials, it could fundamentally change how emergency medicine operates.
But the path from study to deployment is long. Regulatory approval, liability frameworks, physician acceptance, patient trust, and integration with existing hospital systems all stand between a promising research result and an AI tool that actually helps real patients.
For now, the study is a milestone the most rigorous evidence to date that AI can outperform doctors in at least one critical clinical setting. What the medical system does with that evidence will define the next chapter of AI in healthcare.





