
Google Research has introduced TurboQuant, a new compression algorithm designed to dramatically reduce the memory footprint of large language models and vector search engines without sacrificing accuracy. The research was authored by Amir Zandieh and Vahab Mirrokni and is set to be presented at ICLR 2026.
The Problem TurboQuant Solves
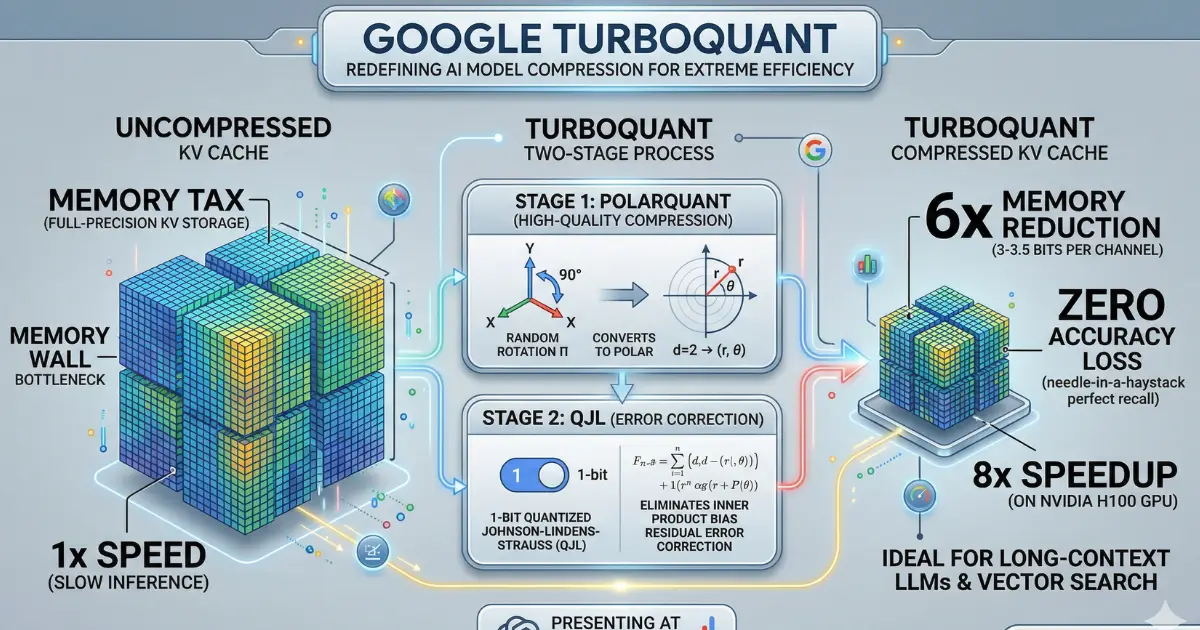
High-dimensional vectors are incredibly powerful for AI applications, but they consume vast amounts of memory, creating bottlenecks in the key-value (KV) cache essentially the short-term memory that AI models rely on for fast information retrieval. Traditional vector quantization methods attempt to compress this data but introduce their own memory overhead, requiring 1 or 2 extra bits per number to store quantization constants, which partially defeats the purpose of compression.
How It Works
TurboQuant achieves high compression with zero accuracy loss through two key steps.
First, using a method called PolarQuant, it randomly rotates data vectors to simplify their geometry, making it easier to apply standard quantization to each part of the vector individually. PolarQuant takes an innovative approach by converting vectors from standard Cartesian coordinates into polar coordinates comparable to replacing "Go 3 blocks East, 4 blocks North" with "Go 5 blocks total at a 37-degree angle." This eliminates the expensive data normalization step that traditional methods require.
Second, TurboQuant uses the QJL (Quantized Johnson-Lindenstrauss) algorithm to clean up any residual error from the first stage using just 1 bit. QJL reduces each vector number to a single sign bit (+1 or -1), creating a high-speed shorthand that requires zero memory overhead while maintaining accuracy through a specially designed estimator.
Impressive Benchmark Results
The research team tested all three algorithms across multiple standard benchmarks using open-source models. TurboQuant achieved perfect downstream results across all benchmarks while reducing KV memory size by at least 6x.
Perhaps most impressively, TurboQuant proved it can quantize the key-value cache to just 3 bits without requiring any training or fine-tuning and without compromising model accuracy. On the hardware side, 4-bit TurboQuant achieved up to an 8x performance increase over 32-bit unquantized keys on NVIDIA H100 GPU accelerators.
For vector search applications, TurboQuant consistently achieved superior recall ratios compared to state-of-the-art baseline methods, even though those baselines used larger codebooks and dataset-specific tuning.
Why It Matters
The implications extend well beyond academic benchmarks. As AI models grow larger and more resource-hungry, efficient compression becomes critical for real-world deployment. TurboQuant addresses this need at a fundamental level.
Modern search is evolving beyond keywords to understand intent and meaning, which requires vector search the ability to find the most semantically similar items in databases containing billions of vectors. TurboQuant enables building and querying these massive vector indices with minimal memory, near-zero preprocessing time, and high accuracy.
The researchers emphasize that these methods are not just practical engineering solutions but fundamental algorithmic contributions backed by strong theoretical proofs, operating near theoretical lower bounds. This mathematical rigor makes them robust and trustworthy for deployment in critical, large-scale systems.
Looking Ahead
While a major application is solving the KV cache bottleneck in models like Gemini, the impact of efficient vector quantization extends further across Google's products. As AI becomes increasingly integrated into everything from language models to semantic search, foundational work in vector compression like TurboQuant will only grow more essential.
The research was conducted in collaboration with researchers from Google, Google DeepMind, KAIST, and NYU. The TurboQuant paper, along with the QJL and PolarQuant papers, are all available on arXiv.





